
Overall students did very well on this assignment. Grades and comments have been committed to the repository. I also added my hmwk5.py file to the repository under resources/homework.
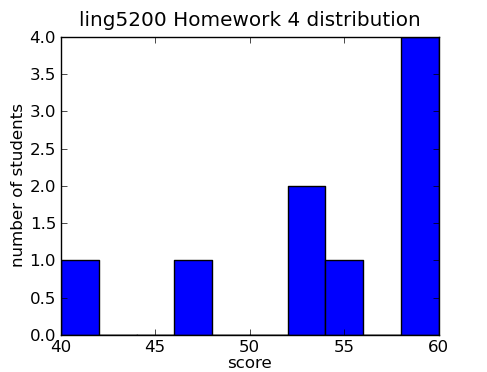
| mean | 53.67 |
|---|---|
| standard deviation | 6.76 |
-
Create a list called my_ints, with the following values: (10, 15, 24, 67, 1098, 500, 700) (2 points)
my_ints = [10, 15, 24, 67, 1098, 500, 700]
- Print the maximum value in my_ints (3 points)
print max(my_ints)
- Use a for loop and a conditional to print out whether the value is an odd or even number. For example, for 10, your program should print “10 is even”. (5 points)
for my_int in my_ints:
if my_int % 2 == 0:
print my_int, "is even"
else:
print my_int, "is odd" - Now create a new list called new_ints and fill it with values from my_ints which are divisible by 3. In addition, double each of the new values. For example, the new list should contain 30 (15*2). Use a for loop and a conditional to accomplish this task. (5 points)
new_ints = []
for my_int in my_ints:
if my_int % 3 == 0:
new_ints.append(my_int*2)
print new_ints - Now do the same thing as in the last question, but use a list expression to accomplish the task. (5 points)
new_ints = [my_int*2 for my_int in my_ints if my_int % 3 == 0]
print new_ints - Import the Reuters corpus from the NLTK. How many documents contain stories about coffee? (4 points)
import nltk
import nltk.corpus
from nltk.corpus import reuters
print len(reuters.fileids('coffee')) - Print the number of words in the Reuters corpus which belong to the barley category. (5 points)
print len(reuters.words(categories='barley'))
- Create a conditional frequency distribution of word lengths from the Reuters corpus for the categories barley, corn, and rye. (8 points)
reuters_word_lengths = [(category, len(word))
for category in ['barley', 'corn', 'rye']
for word in reuters.words(categories=category)]
reuters_word_lengths_cfd = nltk.ConditionalFreqDist(reuters_word_lengths) - Using the cfd you just created, print out a table which lists cumulative counts of word lengths (up to nine letters long) for each category. (5 points)
reuters_word_lengths_cfd.tabulate(samples=range(1,10),cumulative=True)
- Load the devilsDictionary.txt file from the ling5200 svn repository in resources/texts into the NLTK as a plaintext corpus (3 points)
from nltk.corpus import PlaintextCorpusReader
corpus_root = 'resources/texts'
wordlists = PlaintextCorpusReader(corpus_root, 'devilsDictionary.txt') - Store a list of all the words from the Devil’s Dictionary into a variable called devil_words (4 points)
devil_words = wordlists.words('devilsDictionary.txt')
- Now create a list of words which does not include punctuation, and store it in devil_words_nopunc. Import the string module to get a handy list of punctuation marks, stored in string.punctuation. (5 points)
import string
devil_words_nopunc = [word for word in devil_words if word not in string.punctuation] - Create a frequency distribution for each of the two lists of words from the Devil’s dictionary, one which includes punctuation, and one which doesn’t. Find the most frequently occuring word in each list. (6 points)
devil_fd = nltk.FreqDist(devil_words)
devil_nopunc_fd = nltk.FreqDist(devil_words_nopunc)
print devil_fd.max()
print devil_nopunc_fd.max()